Research Interests
Areas of main interest
- Data mining and text mining
- Modeling data quality
- Development of new robust procedures
- Statistical computing
- Bioinformatics
Current Research
I am currently interested in data mining and statistical computing. I developed a
fruitful collaboration with researchers in Computer Science including Raymond Ng, Alan
Wagner and Laks Lakshmanan. We are co-supervising several graduate students who are
working on different data mining problems. A paper that resulted from this collaboration
won the "Best Paper Award" in the KDD 2001 Conference. We are now working on the
scaling of robust algorithms using parallel computing, on text mining and compression of
large relational databases.
In collaboration with several computer scientists (Ng, Lakshmanan and Wagner from UBC
and Rosenthal and Sevcik from University of Toronto) we obtained MITACS funding for the
project "Toward Interactive Data Mining". Our MITACS project has two main
industrial partners: Insightful Corporation (the producer of Splus and I Miner) in the
first year and IBM through a collaboration with the iCAPTURE Centre at the St Paul's
Hospital in the second year.
I am very interested in the study and modelling of data quality in the context of
large, high dimensional datasets. Together with my former student, Fatemah Alqallaf, we
proposed a new, flexible model to represent contamination in multivariate data. This model
brings up a new phenomenon that we call "outlier propagation", which may become
an important concept regarding the robust analysis of high dimensional datasets.
I developed a very fruitful collaboration with Dr. McManus and his medical group and
participate in several projects involving IBM and iCAPTURE. Professor McManus is the
Co-Director of iCAPTURE Centre and Director of the Cardiovascular Research Laboratory and
the Cardiovascular Registry, Department of Pathology and Laboratory Medicine. I am an
active collaborator in an exciting medical project entitled "Better Biomarkers of
Acute and Chronic Allograft Rejection" which recently gained $9.1 million of funding
over three years. This project will generate very interesting problems as well as
financial support for several of our students and possibly one or two postdoctoral
fellows.
My collaboration with iCAPTURE has been facilitated by the appointment of a
statistician, Rong Zhu, as a post-doctoral fellow under my supervision, jointly with Ng.
This appointment was funded by iCAPTURE and the Pacific Institute of Mathematical Sciences
(PIMS). I am also helping iCAPTURE to develop a new exciting project entitled iIMPAC
(Integrated Information Management Platform Across Canada).
Some Contributions to the Theory of Robustness
When I started my research career in 1986 I was mainly interested in the general theory
of quantitative robustness, which was dominated by the concepts of influence function and
breakdown point. I thought that these measures of quantitative robustness gave a rather
incomplete assessment of the degree of robustness of an estimate. I thought that a much
better assessment can be made using the concept of maximum asymptotic bias (maxbias)
introduced, for the simple location model (with known scale) by Huber (1964). Huber
quickly abandoned this approach because in his opinion it led to a "rather uneventful
theory". The maxbias approach to robustness was then "dormant" for nearly
20 years until I showed that maxbias functions and minimax estimates can be derived for
the scale, regression and orthogonal regression models. Together with collaborators
(Victor J. Yohai and R. Doug Martin) we showed that the minimax theory can be extended to
linear regression and derived minimax bias robust regression estimates. It is safe to say
that nowadays the maxbias approach is considered the most important theoretical tool in
quantitative robustness. I am now working to show that the maxbias approach can also lead
to of useful statistical procedures, via the construction of bias bounds and global robust
inference (which takes into account the effect of bias caused by data contamination).
Huber (1964) considered the problem of minimax variance for the location model with
known scale. Huber's result has a great mathematical beauty but, in my opinion limited
practical impact because:
- pure location with known scale is a very simple statistical model with little (if any)
practical value
- symmetric contamination neighborhoods (considered by Huber) are very restrictive and in
clear contradiction with the robustness approach
I worked to remedy these limitations. Together with collaborators (V.J. Yohai, J.
Adrover, J.R. Berrendero and M. Salibian) we developed a new globally robust confidence
intervals of minimax length and initiated the new robustness theory which we call "global robust inference". The aim of global robust inference is
constructing robust confidence intervals, p-values and tests that take into account not
only the uncertainty due to "normal" data variability but also the bias effect
of "abnormal" noise and poor data quality.
Some New Statistical Procedures
 Tau-Estimates: Victor Yohai and I introduced the class of robust
Tau-Estimates: Victor Yohai and I introduced the class of robust 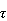 -estimates.
We defined these estimates for the case of linear regression. Now
-estimates.
We defined these estimates for the case of linear regression. Now 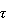 -estimates
have also been defined for multivariate location, orthogonal regression, principal
component, etc.
-estimates
have also been defined for multivariate location, orthogonal regression, principal
component, etc. 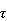 -estimates can attain breakdown point of
1/2 and arbitrary high efficiency at the "target" model.
-estimates can attain breakdown point of
1/2 and arbitrary high efficiency at the "target" model.
Orthogonal Regression M-Estimates: I defined these
estimates and study their robustness properties.
Image Enhancement: Jean Meloche and I
proposed a generally applicable, non-parametric method to enhance and restore binary
images.
Robust (Fast) Bootstrap: Matias Salibian
and I developed a new bootstrap method to quickly estimate the variability of some
computational intensive robust regression estimates. Our robust bootstrap is not only
several orders of magnitude faster than classical bootstrap but also gives more stable and
reliable variance estimates in the presence of outliers and data contamination.
Linear Grouping Algorithm (LGA): together
with collaborators (Stefan Van Aelst, Steven Wang and Rong Zhu) we proposed a new approach
to clustering where items following similar linear relationship are grouped together.
CLUES: together with collaborators (Steven
Wang and Weiliang Qiu) we proposed a new approach to clustering based in k-near neighbors
averaging. Iteratively, each point is replaced by its local average and the procedure is
continued to convergence.
Pairwise Correlation Matrices: together
with collaborators (Ricardo Maronna and Fatemah Alqallaf ) we proposed several robust
correlation/covariance estimates based on pairwise operations. Two of these methods
(pairwise QC and pairwise GK) are now available in the Splus 6.1 robustness library.
