Lecture 6: Topics in Bayesian non-parametrics
Instructor: Alexandre Bouchard-Côté
Editor: David Lee and Fred Zhang
In these notes, we show examples of how Dirichlet processes can be composed into more complicated (and hopefully, more realistic) models, how they can be generalized (i.e. building large classes of stochastic processes), applied to different setups, and how they can be superseded by other types of stochastic processes.
To motivate some of these extensions, we start by discussing the applications in Natural Language Processing (NLP).
Hierarchical DP (HDP)
Motivation: N-gram Language models
N-gram language models are a type of distributions over sequences of words (where a word is viewed as an abstract symbol $w$ from a finite set $W$, called the alphabet). Sequences of words are often called strings. We denote the set of all possible strings by $W^\star$. For example, if $W = \{$a, b$\}$, then $W^\star=\{\epsilon,~$a, b, aa, ab, ba, bb,$\dots\}$, where $\epsilon$ is the empty string. With this notation, N-gram language models can be described as the probability distributions $\lmodel_k$ over $W^\star$, which can be written as:
\begin{eqnarray} \lmodel_k(\underbrace{w_0,\ldots,w_k}_{w\in W^*})= \prod^{k}_{i=1}\lmodel(\underbrace{w_i}_{\textrm{given word}}|\underbrace{w_{i-n}\ldots w_{i-1}}_{\textrm{prefix of length } n}) \end{eqnarray}
The integer $n$ is fixed, and is called the order of the language model. Here we assume $n=1$, i.e. only the previous word is conditioned upon—this is called a unigram model. The right hand side of the conditioning is called the context.
Language models are used to find which sentence is more likely. To understand why this is useful, here we present a very simplified version of speech recognition model. The task in speech recognition is to estimate a sequence of words corresponding to a sequence of sounds $s$.
In the HMM over words, we have $w_{t+1}|w_{t} \sim \lmodel_1$, while the sound unit given a word, $s_t|w_t$ is modeled by another HMM, this time over smaller signal segments. In practice, the boundary between words are not known (which complicates the model), but the general idea of how language models are used is the same: to disambiguate between similar-sounding words.
For example, the words 'their' and 'there' cannot be told apart from their pronunciation, but they can usually be differentiated by the context in which they are used. Note also that language models can be trained on raw text (which is cheap and available in large quantity online, e.g. from Wikipedia), while training $s_t|w_t$ requires annotated speech data (expensive).
Estimation of language models:
The direct, naive approach to build an n-gram model $\lmodel_1$ is to parameterize each of the $|W|$ multinomial distributions $\lmodel_1(w_i|w_{i-1})$ by a separate vector of parameters, and to estimate these parameters independently using maximum likelihood.
The problem is that this approach results in zero probability for pairs which we have not seen before, even when each word in the pair has been seen (in different contexts). For example, the sequence 'I think' may be given zero probability even though 'they think' and 'I believe' have been observed. This can have dramatic effect in, say, a speech recognition system: a long sentence would be given probability zero even when a single pair has not been seen. Note that in contrast, a context-free model (i.e. an n-gram language model with $n=0$) would give a positive probability to 'I think' given this training data because each word has been observed.
Since the training data is more fragmented to higher order language models, there should be some mechanisms to back off to simpler models. We will accomplish this using a model called the hierarchical Dirichlet process (HDP) (Teh et al., 2004). For pedagogical reasons, before introducing the HDP, we will start by showing how a simple Dirichlet process model as introduced in the previous set of notes could be used to back off to a fixed model (e.g. uniform distribution over words). Next, we will show how the HDP can provide more intelligent back-off distributions, namely lower order n-gram models.
Language model using DPs:
To address the aforementioned problem, we introduce the following model, a Dirichlet process with base measure equal to the uniform distribution over $W$: \begin{eqnarray} \pi^u &\sim& \gem(\alpha_0) \ \textrm{(stick breaking dist.)}\\ \theta^{u}_{c} &\sim& G_0 \ \textrm{where } G_0 = \unif(W)\\ x^{u}_{n}|\pi^u &\sim& \mult(\pi^u)\\ y^{u}_{n}|x^{u}_{n},\theta^{u} &\sim& \delta_{(\theta^{u}(x^{u}_{n}))} \end{eqnarray} Here $y^{u}_{i}$ is a word following prefix $u$ (from now on, we use the superscript to annotate the prefix/context under which the next word has to be predicted), and \delta_{(\theta^{u}(x^{u}_{n}))} is the Dirac delta function.
In the directed graphical model notation, this looks like the following:
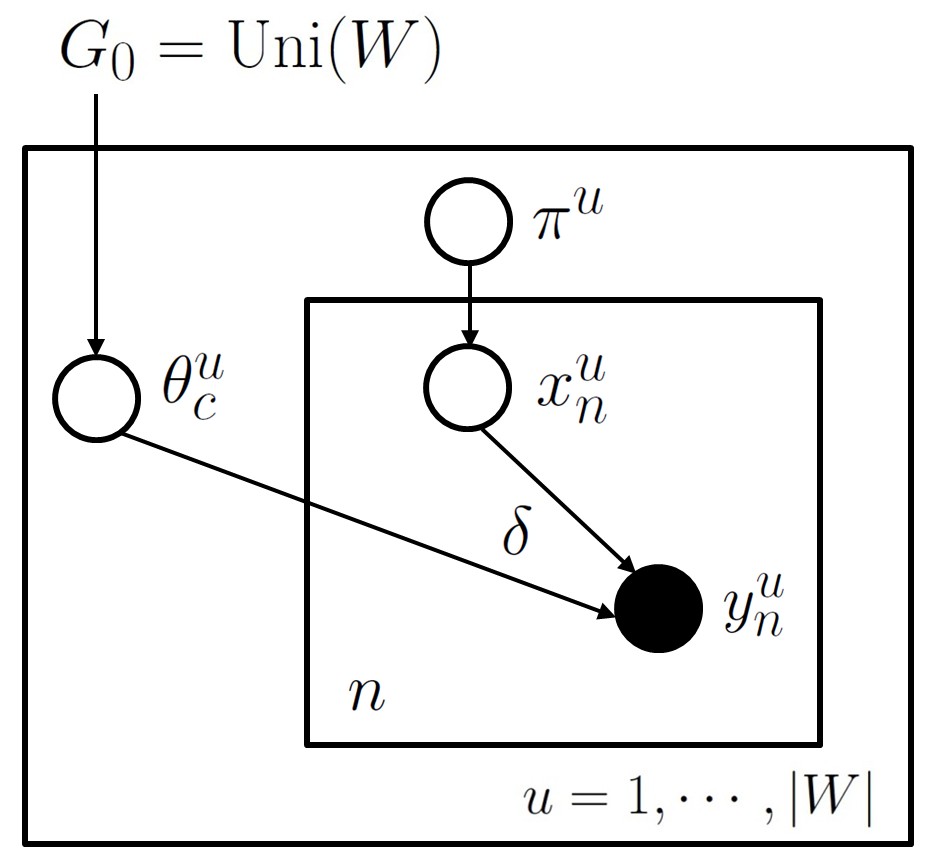
A more compact way to write this is: \begin{eqnarray} G^{u} &\sim& \dirp(\alpha_0, \unif(W))\\ y^{u}_{n}|G^{u} &\sim& G^u. \end{eqnarray}
Note that, in contrast to the previous mixture modeling/clustering example, the likelihood model here is a simple, deterministic function of the dish for the table: a Dirac delta on that dish. Concretely, a dish is a word type, and customers simply have this word associated with them deterministically. This implies that, given a table assignment, the dishes at each table are observed, which simplifies probabilistic inference.
Note that this model never assigns a zero probability to words in $W$ (even when the word was not observed in the context) since the probability of a new word (i.e. creating a new table in CRP) is positive. Now suppose we have the following observations and table assignments for one of the contexts $u$:
\begin{eqnarray} x^{u}_{1} \ldots x^{u}_{n} &\longleftarrow& \textrm{table assignments} \\ w^{u}_{1} \ldots w^{u}_{n} &\longleftarrow& \textrm{words} \end{eqnarray}
then it can be shown (easy exercise) that generating a new word is done using the following probabilities:
\begin{eqnarray} \underbrace{w^{u}_{n+1}}_{\textrm{new customer}}|x^{u}_{1},\ldots,x^{u}_{n} &\sim& \textrm{1. create new table; dish sampled from } G_0\textrm{ with prob.} \frac{\alpha_0}{\alpha_0+n} \textrm{, OR,} \\ && \textrm{2. use a dish } w \textrm{ from existing tables with prob.} \frac{n^{u}_{w}}{\alpha_0+n} \end{eqnarray} in which $n^{u}_{w}$ is the number of times $w$ was observed in all the training data $w^{u}_{1} \ldots w^{u}_{n}$.
Note that in this setting, to do prediction we only need to know, for each context, the number of times each word appeared in the text. Consequently, we can marginalize the table assignments and there is no MCMC sampling required in this special case (this will not be true in the following models).
HDP models
A problem with the approach of the previous section is that the back-off model, the uniform distribution, is not very good. A better option would be to back off to a context-free distribution over words. One way to achieve this is to use the MLE over words in the corpus instead of the uniform distribution as the base measure. This approach is called the empirical Bayes method. Here we explore an alternative called the hierarchical Bayesian model.
The basic idea behind HDPs is to let the base measure be itself a Dirichlet process: \begin{eqnarray} G &\sim& \dirp(\alpha_0, \unif(W))\\ G^u|G &\simiid& \dirp(\alpha^{u}_{0}, G)\\ w^{u}_{n}|G^{u} &\sim& G^{u} \end{eqnarray}
In the directed graphical model notation, this looks like (recall that boxes, called plates, mean repetition of the variables inside the box) the following:
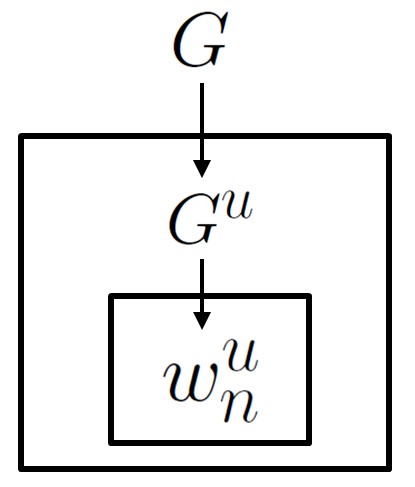
To make this model clearer, we will provide two equivalent ways of generating samples from it: as in the standard DP, both stick breaking and CRP constructions are possible.
Let us start with the stick breaking way. We will describe the generative process by referring to the following figure:
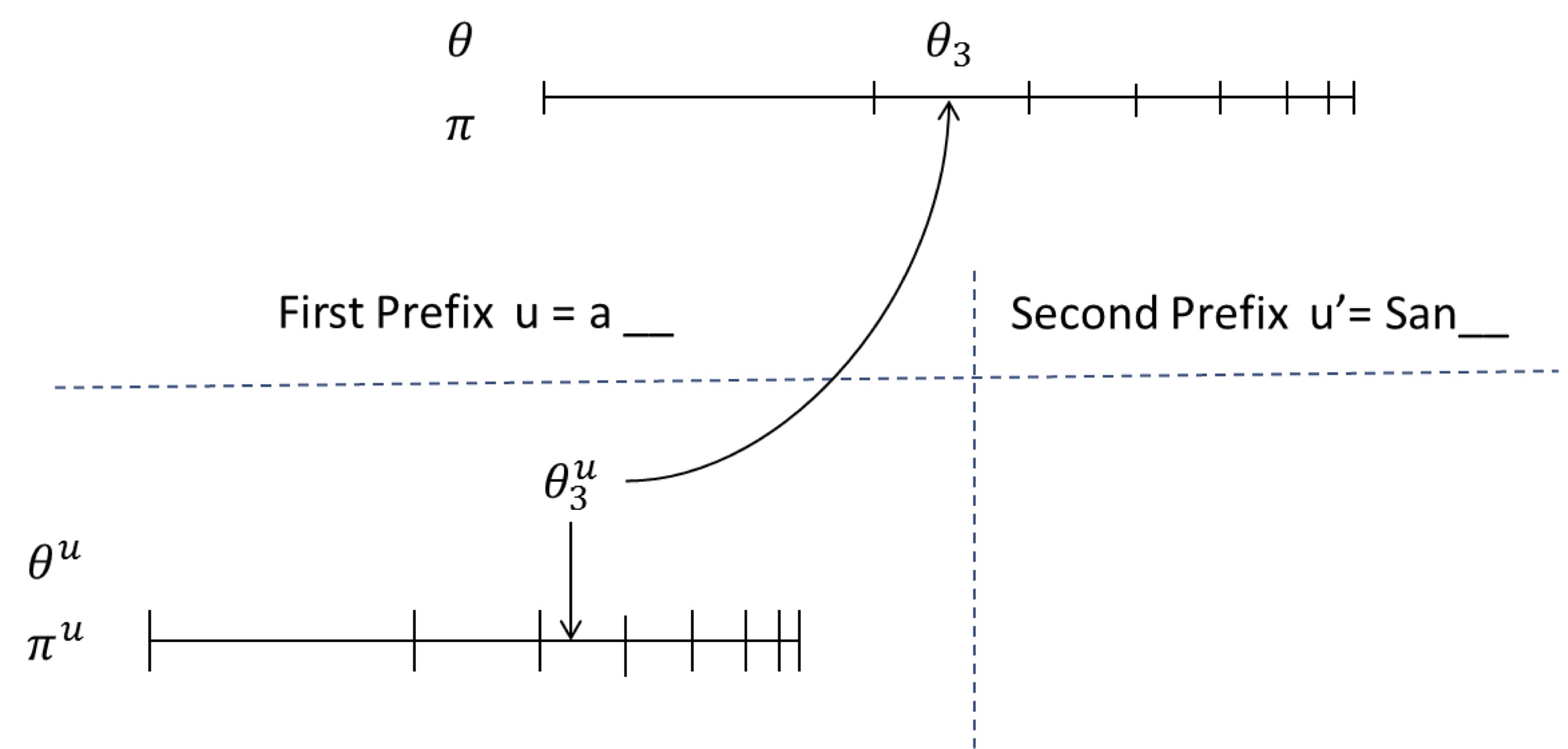
There is one set of sticks for each prefix (one of them is shown below the horizontal dashed line), and one global set of stick (above the horizontal dashed line) corresponding to the context-free model.
To sample from the first prefix in the figure above:
- Throw a dart on the prefix-specific stick $\pi^u$
- If it ends up in segment $c$ (e.g. $c=3$ here), sample $c$ beta random variables to construct the first few sticks
- Extract $c$ samples from $G$, return the third one. $G$ can be sampled from using the following steps (the usual DP):
- Throw a dart on $\pi$,
- If it end up in segment $c'$ (e.g. $c'=2$ here), sample $c'$ beta random variables to construct the first few sticks
- Generate $\theta_1, \dots, \theta_{c'}$ from $\unif(W)$. Here $\theta_{c'}$ is the first realization of $G$. Repeat the process to generate $c=3$ realizations from $G$. Return $\theta_3$.
When the next sample is needed, only generate new sticks and base measure samples if the dart falls outside the region that was generated so far. This means that samples from $G_0$ are needed only when both the dart on the context specific and global sticks fall outside the sticks already generated.
Another way to view this process is the Chinese Restaurant Franchise. In the Chinese restaurant franchise, the metaphor of the Chinese restaurant process is extended to allow multiple restaurants to share a set of dishes.
We will refer to the following figure:
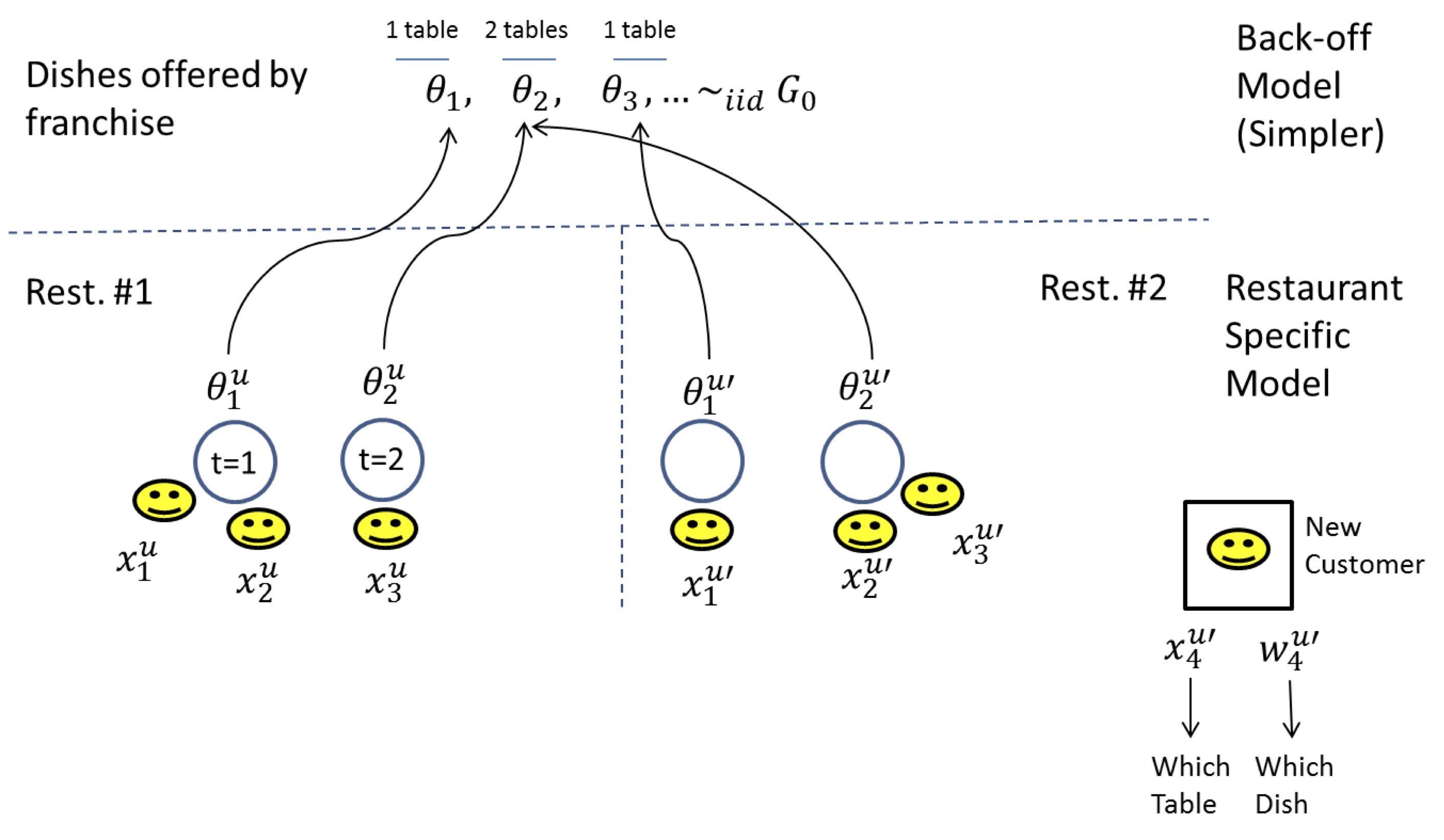
Here each context (prefix) corresponds to a restaurant. The same dish can be served across many restaurants (hence the franchise terminology).
For a new customer entering say in the second restaurant (i.e. $x^{u'}_{4},w^{u'}_{4}|x^{u'}_{1:3},w^{u'}_{1:3},x^{u}_{1:3},w^{u}_{1:3}$) the sampling process can be summarized by the following decision tree:
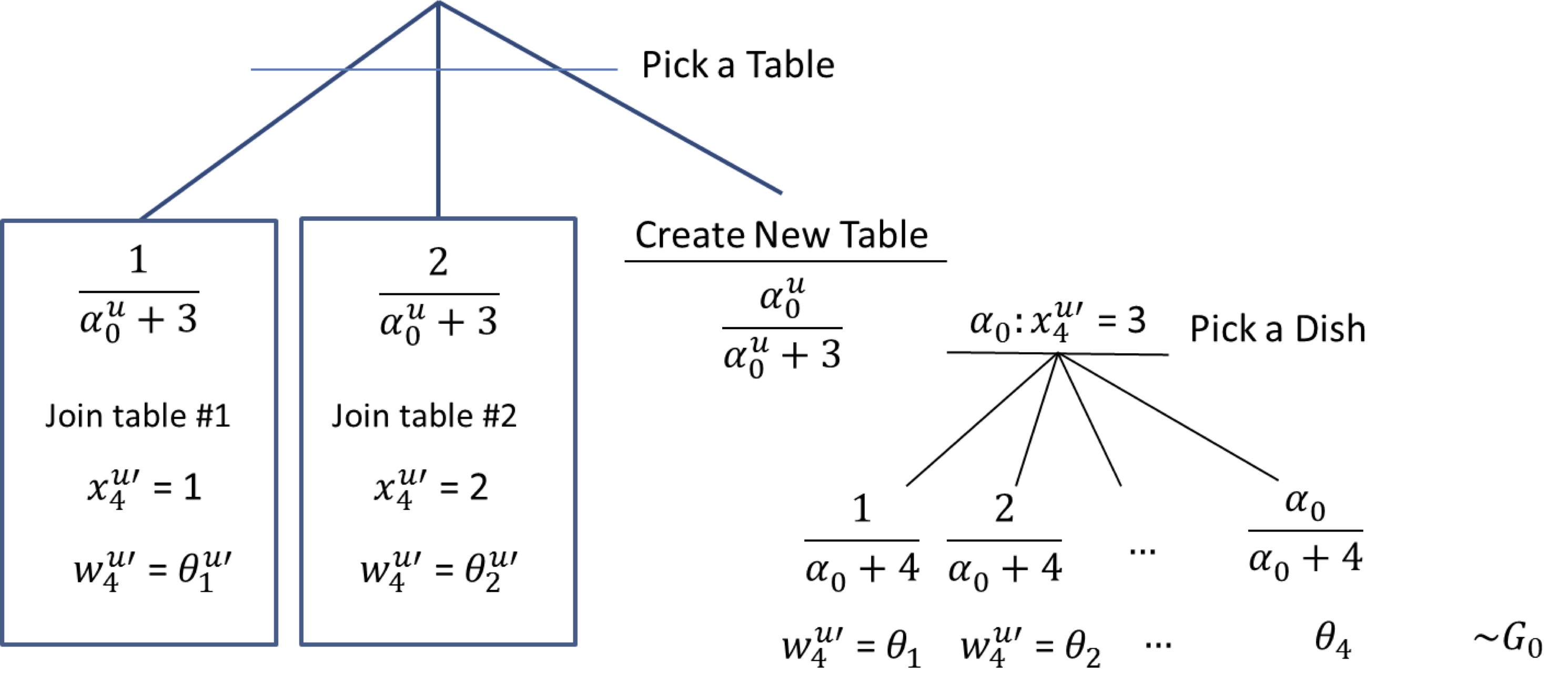
In other words, the customer first picks if he will join an existing table in the current restaurant (with probability proportional to the number of people at that table), or create a new table (with probability equal to $\alpha^{u}_0/(n_{\textrm{cust. in rest.}}+\alpha^{u}_0)$, where $n_{\textrm{cust. in rest.}}$ is the number of customers in the current restaurant). In the former case, the dish is the same as the one served at the picked table, in the latter case, another dish needs to be sampled. It has the same structure, but this time existing dishes are sampled with probability proportional to the number of tables that picked that dish, across all restaurants. A new dish can also be sampled with probability equal to $\alpha_0/(n_{\textrm{tables}}+\alpha_0)$, where $n_{\textrm{tables}}$ is the number of tables across all restaurants.
DP for GLMs
We now outline an application of DPMs on regression and clustering. This application was described in Hannah et al., 2011.
The goal is to transform a global (generalized) linear model into a local (generalized) linear model, within a Bayesian framework. For example, instead of getting a fit as shown on the left in the figure below, we would like a collection of locally linear fits (on the right):

We start by reviewing standard Bayesian regression (for more detailed introduction, see Gelman, 2004 or Robert, 2007), and then we will introduce the DPM approach.
A basic Bayesian linear regression model has the following form:
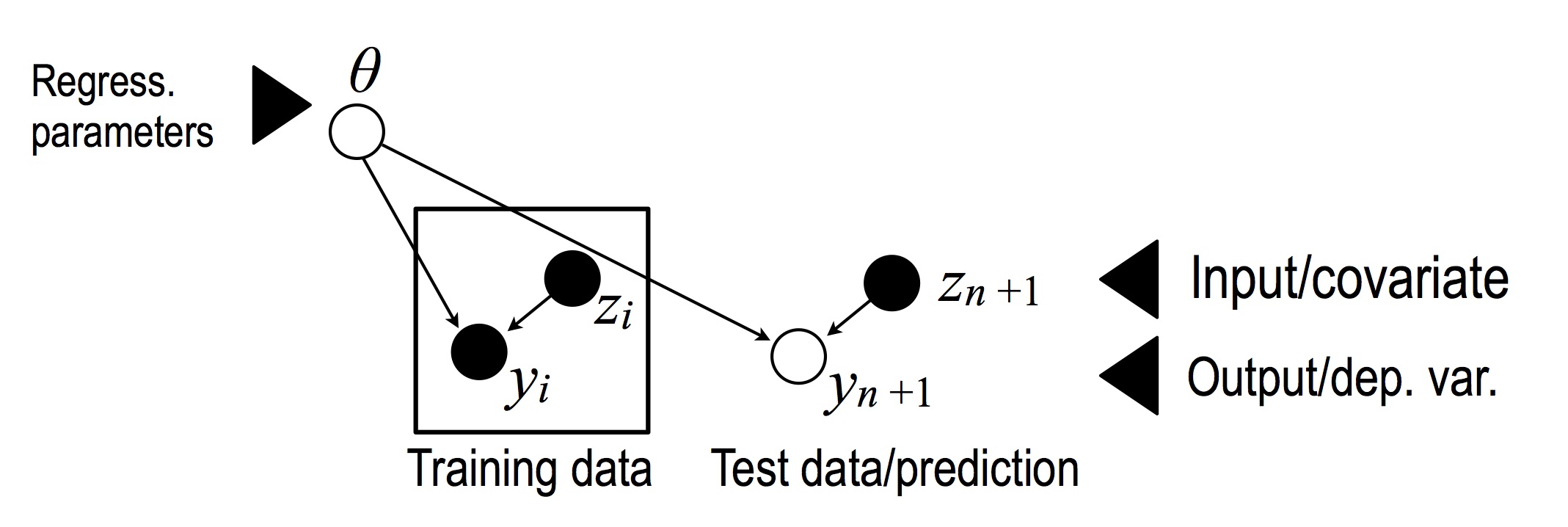
where $z_i$ is a $D$-dimensional vector of input/covariates, $\theta$ is a $D$-dimensional parameter vector and $y_i$ is a 1-dimensional response say. Let $Z$ denote the $n$ by $D$ data matrix, and $Y$, the $n$ by $1$ training responses. We put the following distributions on these variables: \begin{eqnarray} \theta^{(d)} &\sim& N\left(0, \textrm{precision}=\tau_2\right), \text{ } d = 1, \ldots, D.\\ y_i|\theta, z_i &\sim& N\left(\dotprod{\theta}{z_i}, \textrm{precision}=\tau\right). \end{eqnarray} where $\tau$ is a noise precision parameter, and $\tau_2$ is an isotropic parameter regularization.Note that this model does not depend on the prior on the covariates. This has motivated G-priors (Robert, 2007) with parameters that depend on $Z$, which allow putting a prior over the precision parameters considered fixed in the model above. On the other hand, in the DPM extension that will follow shortly, we will need to put a distribution on the input variable, since new datapoints will be assigned to a cluster using this distribution, which will then allow using the most appropriate set of regression parameters with higher probability.
By conjugacy, we get the following posterior on the parameters: \begin{eqnarray} \theta|y_{1:n},z_{1:n} &\sim N(M_n, S_n) \\ \end{eqnarray} where \begin{eqnarray} S_n & =& (\tau_2 + \tau \transp{Z}\ Z)^{-1}\\ M_n &=& \tau S_n \transp{Z}\ Y. \end{eqnarray}
Background: How to derive these types of equations? Intuitively, this follows from a trick known as "completing the square", which is often used to establish conjugacy in normal models. We show a simple univariate example here.
We first show that posterior $\theta|y,z$ is normal. Since the posterior density over $\theta$ is proportional to the joint density, it is enough to show that \begin{eqnarray}\label{eq:compl1} \underbrace{\exp\left( a \sum_i (y_i - \theta z_i)^2 \right)}_{\propto\ \textrm{ likelihood}} \underbrace{\exp\left( b \theta^2\right)}_{\propto\ \textrm{ prior}}, \end{eqnarray} where $a,b < 0$, is proportional to an expression of the form \begin{eqnarray} \exp( c \theta^2 + d \theta + e), \end{eqnarray} where $c$ should be negative. But by polynomial multiplication this is clearly true, with $c = b + a \sum_i z_i^2 < 0$.
Next, to find the updated parameters of this posterior normal density, all we need to do is to rewrite our expression a second time, now into \begin{eqnarray} \exp(- h^2 (\theta - k)^2). \end{eqnarray} This is done by completing the squares, i.e. noting that a constant can be added to the quadratic form: \begin{eqnarray}\label{eq:compl2} \exp( c \theta^2 + d \theta + e) &=& \exp\left( c \theta^2 + d \theta + e + f - f\right) \\ &\propto& \exp\left( c \theta^2 + d \theta + e + f\right). \end{eqnarray}
Now that we have shown that Equation~(\ref{eq:compl1}) is proportional to Equation~(\ref{eq:compl2}), we are done since this expression is proportional to a normal density with precision $h$ and mean $k$, and is therefore equal (this argument sidesteps the difficulties of computing complicated normalization constants).
To generalize this argument to the multivariate setting, one can use the Schur complement.
Given a new covariate $z_{n+1}$, the predictive distribution over $y_{n+1}$ is then: \begin{eqnarray} y_{n+1}|z_{n+1}, y_{1:n}, z_{1:n} & \sim& N(\transp{M_n}\ z_{n+1}, \sigma_n^2(z_{n+1})) \end{eqnarray} where $\sigma^2_n(z) = \frac{1}{\tau} + \transp{z}\ S_n\ z$.
We now turn to the non parametric version of this model, which has the following graphical model:
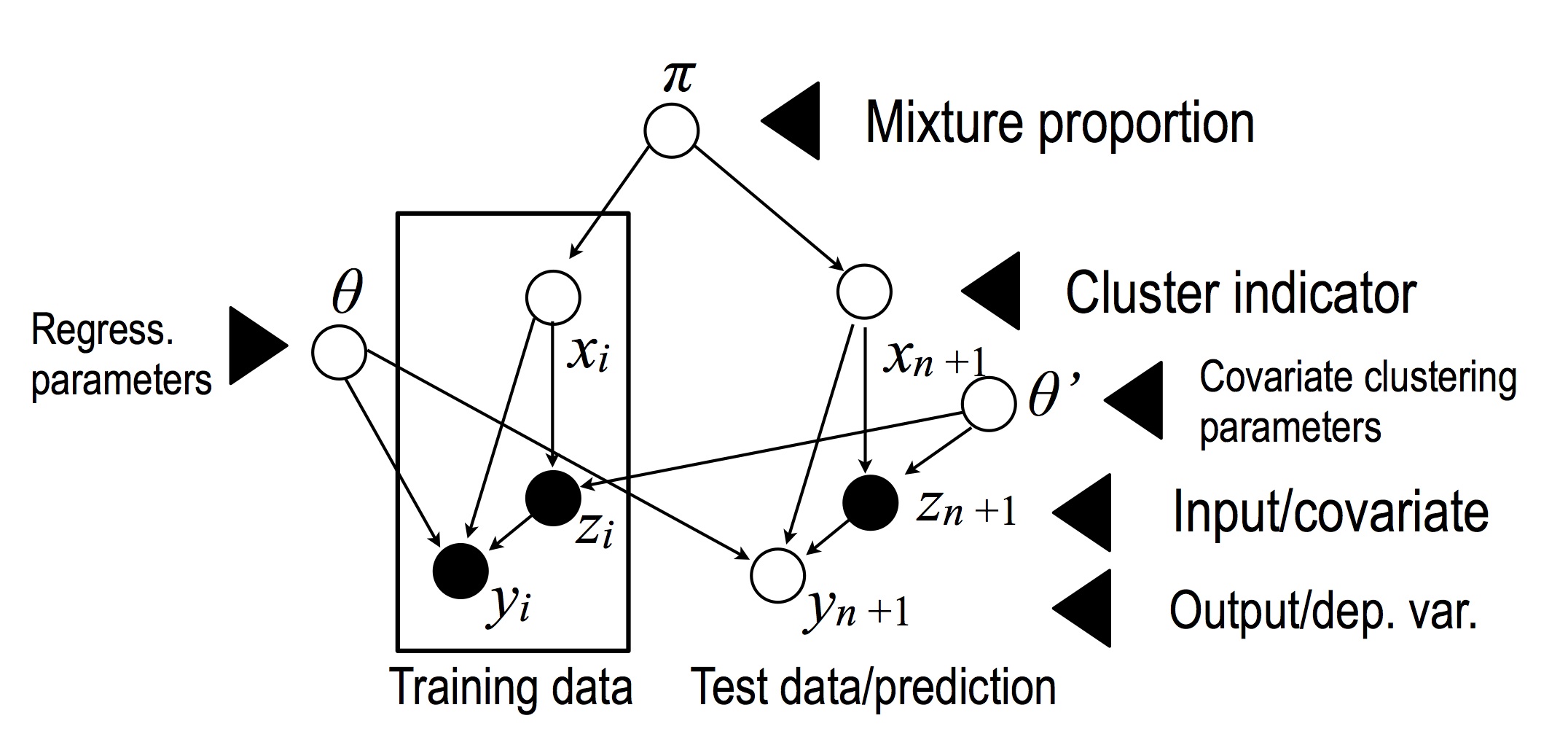
where $\theta_c = (\theta^{(1)}_c, \dots, \theta^{(D)}_c)$ are vectors of regression parameters, and $\theta'_c = (\theta'^{(1)}_c, \dots, \theta'^{(D')}_c)$ are vectors of clustering parameters.
This model seems complicated at first glance, but note that a standard DPM model on the covariates appears as a submodel:
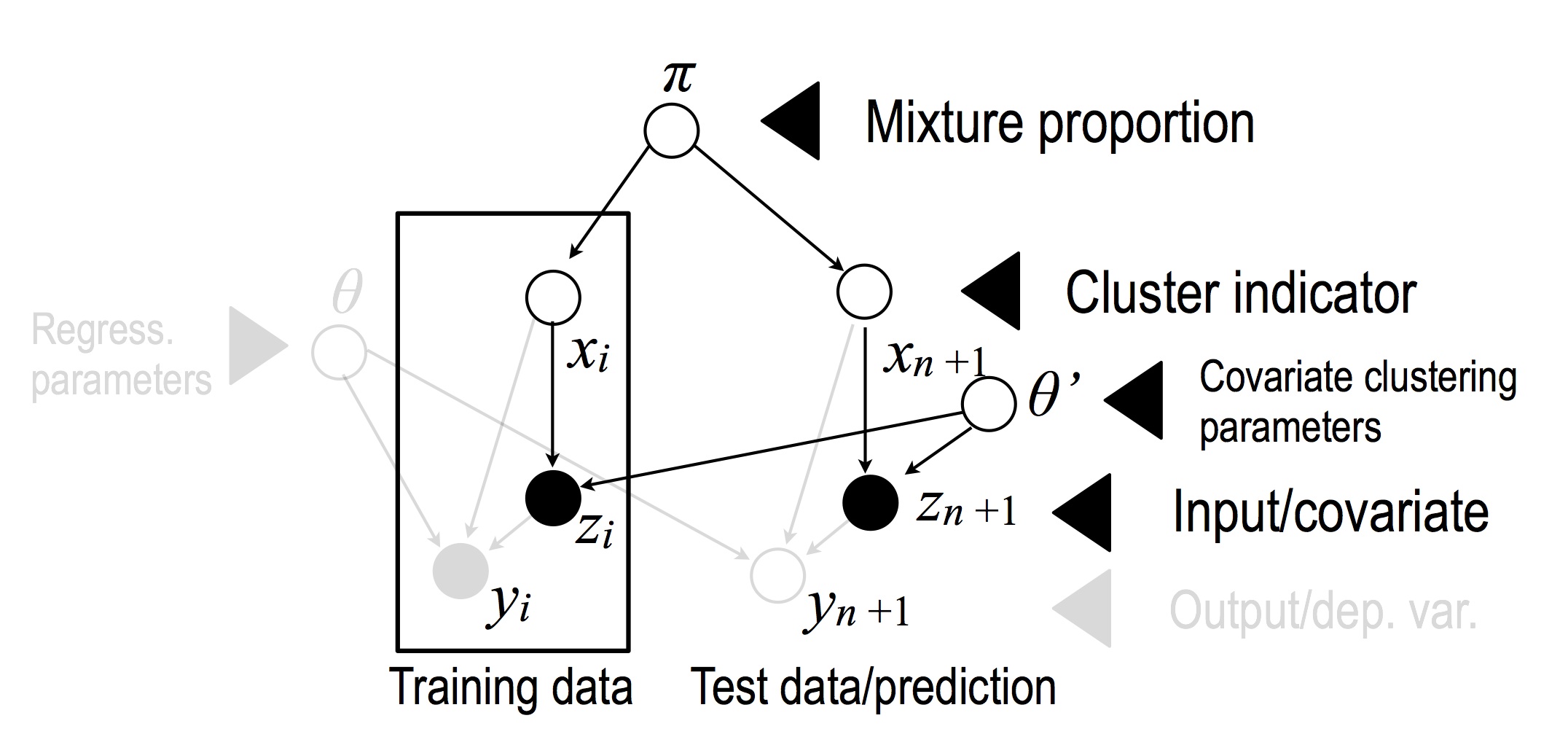
The rest of the model is the same as the standard (parametric) Bayesian regression model, but with the set of parameter determined by the cluster indicator.
The intuitive idea is that, given a new datapoint, the prior over the $z$'s enable us to get a posterior over which cluster it belongs to. For each cluster, we have a standard Bayesian linear regression model.
Formally, we define the distributions as follows: \begin{eqnarray} \pi &\sim& \gem(\alpha_0) \\ x_i|\pi & \sim &\mult(\pi)\\ \theta_c^{'(d)} & \sim & N\left(0, \textrm{precision}=\tau_3\right), d = 1, \dots, D'; c = 1,2,\ldots\\ \theta_c^{(e)} &\sim& N\left(0, \textrm{precision}=\tau_2\right) \text{ } e=1, \ldots, D\\ z_i | \theta', x_i & \sim & N\left(\theta'_{x_i}, \textrm{precision}=\tau_4\right), \text{ } i= 1, \ldots, n+1\\ y_i|z_i,x_i,\theta &\sim& N\left(\dotprod{\theta_{x_i}}{z_i}, \textrm{precision}=\tau\right), \end{eqnarray} where $\tau_3$ acts as a regularization on the clustering parameter, and $\tau_4$ as a noise precision parameter on the input variables.
Note that simulating the posterior of the cluster variables can be done using collapsed sampling by conjugacy. Given such samples $x_{1:n_1}^{(s)}$, the regression estimator under $L^2$ loss on $y$ takes the form: \begin{eqnarray} \E(y_{n+1}|D) &=& E[E[y_{n+1}|D, x_{1:(n+1)}]]\\ &\approx& \frac{1}{S} \sum^S_{s=1} \E[y_{n+1}|D, x_{1:(n+1)}^{(s)}]\\ &=& \frac{1}{S} \sum^S_{s=1} \transp{(M_n( x_{1:(n+1)}^{(s)}))} z_{n+1}, \end{eqnarray} where $D$ denotes the training data (inputs and outputs) as well as the new input $x_{n+1}$. The posterior mean takes a form similar to the parametric case, but defined on the subset of datapoints in the same cluster as the new data point in the current sample:
\begin{eqnarray} S_n(x_{1:(n+1)}) & = & (\tau^2 + \tau \transp{Z(x_{1:(n+1)})}\ Z(x_{1:(n+1)}))^{-1}\\ M_n(x_{1:(n+1)}) &=& \tau S_n(x_{1:(n+1)}) \transp{Z(x_{1:(n+1)})}\ Y. \end{eqnarray} where \begin{eqnarray} Z(x_{1:n}) = \left[ \begin{array}{c} -\textrm{ } z_{i_1} -\\ \vdots \\ -\textrm{ } z_{i_k} -\\ \end{array} \right] \end{eqnarray} and $(i_1,\ldots,i_k)$ are the indices of the data matrix rows in the same cluster as $x_{n+1}$.
See Hannah et al., 2011 for a generalization of this idea to other GLMs, including an application to classification.
Readings in preparation for next topics
I will do a very quick review of 2-3, but if you haven't taken 547C with me (or equivalent), it is a good idea to do some pre-readings (and/or to ask your colleagues that did take 547C to help you).
- MCMC. Many tutorial available on the web, for example Andrieu et al., 2003. For a video presentation: Murray, 2009.
- Importance sampling and SMC. Many tutorial available on the web, for example Doucet and Johansen or Doucet, 2010.
- Poisson processes: Kingman, 1993. Very readable. Skim these chapters if you can: 1-5, 8-9.
Supplementary references and notes
Hjort NL, Holmes C, Müller P, Walker SG (2010) Bayesian Nonparametrics, Cambridge University Press. Relevant parts include sections 5.1, 5.2, 5.4 and 5.7.1.
Machine Learning - 2007 Advanced Tutorial Lecture Series, Department of Engineering, University of Cambridge. Slides by Teh YW on DP and HDP: Link
Escobar MD, West M, Bayesian Density Estimation and Inference Using Mixtures. Journal of the American Statistical Association, Volume 90, Issue 430, 1995, pp. 577-588.